
21 Software Engineering Principles for Effective AI Coding
Making Claude adhere to proven best practices

A few weeks into building with an AI coding assistant full-time, I noticed something that bothered me more than any bug.
The code mostly worked. That wasn’t the problem. The problem was everything that happened between my prompt and the finished diff — the dozens of small decisions the model made on my behalf and never mentioned. It picked a caching strategy. It chose to store a timestamp as a string. It added a dependency. It decided this endpoint didn’t need rate limiting. It refactored a helper I didn’t ask it to touch.
Each choice was defensible in isolation. Collectively, they meant I was no longer the engineer on my own project. I was a reviewer of a stranger’s pull request — one who never explained his reasoning and had already moved on.
That’s the real risk of AI-assisted development. Not that it writes bad code. It writes fine code. The risk is that it makes silent decisions — and a hundred silent-but-reasonable decisions add up to a system nobody actually designed. Also, there are proven software engineering best practices (beyond just coding) that don’t need get thrown out along with the bath water.
So I wrote down a set of rules to fix it. Twenty-one of them. They’re now the first thing my assistant reads in every session, and I’ve put them in a public repo (link at the bottom). This post is the why behind them.
The one idea underneath all of it
If I had to compress the whole framework into a sentence, it’s this:
Surface tradeoffs, don’t silently decide.
Almost every rule is a specific instance of that principle. The model is allowed to have opinions — I want its opinions — but it has to show me the fork in the road before it picks a direction. The goal is to make me a participant in the design, not a spectator to a finished diff.
That reframing changes the relationship. A black box hands you an answer. A good collaborator says, “Here’s what I’d do, here’s the alternative, here’s the tradeoff — your call.” I want the second one. Every time.
Decisions should happen before the code, not after
The most expensive bugs aren’t typos. They’re logic flaws and design mistakes you don’t catch until the feature is built, deployed, and being used the wrong way.
So three of my rules push validation earlier than code:
Get the requirements straight first. If what I’m asking for is ambiguous, the model’s job is to stop and ask, not to guess and build. Ambiguity at the start compounds into rework at the end. “I’ll figure it out as I go” is a red flag, not a work ethic.
Mock the UI in HTML before building it. For any non-trivial interface, I want a static HTML mockup — colors, layout, spacing, real visual states — before a single production component gets written. Approving a direction takes thirty seconds. Rebuilding a feature because the layout was wrong takes a day.
Prototype the logic before implementing it. This one’s my favorite, and it’s the one people skip. For anything with real business logic — an approval flow, a branching journey, a pricing calculation, a routing decision — I want a clickthrough HTML prototype that simulates the workflow end to end. Not for UI polish. For logic validation. I click through the branches, the edge cases, the error paths, and I confirm: yes, this is the logic I want — on disposable HTML, before anyone sinks time into real code.
Catching a logic flaw on a throwaway prototype costs minutes. Catching it in production costs a weekend and your users’ trust.
The things AI quietly gets wrong
A few rules exist specifically because of failure patterns I kept seeing.
It invents its own conventions. Left alone, an AI assistant writes code in its preferred style, not your codebase’s. Different naming, different error handling, different file structure — a slow drift that makes a codebase feel like it was written by five different people. So the rule is explicit: study the conventions already in use, and match them. Deviation requires a reason.
It refactors things you didn’t ask it to touch. “While I was in there, I also cleaned up…” is how a one-line fix becomes a forty-line diff that breaks three things you weren’t thinking about. My rule: do only what was asked. See something worth fixing? Surface it as a follow-up — don’t smuggle it into the current change.
It claims things work when it didn’t check. This is the one that erodes trust fastest. “Done!” should mean verified, not probably fine. So I make the model distinguish between “I wrote the code,” “it compiles,” and “I confirmed the behavior end to end” — and say plainly when it couldn’t verify something because it had no dev server, no real data, no credentials. “I changed X but couldn’t verify Y, please confirm” is worth more than a confident lie.
The part that keeps it from becoming bureaucracy
Here’s the honest objection: twenty-one rules sounds exhausting. If every “fix this typo” kicks off a tradeoff analysis and three clarifying questions, the cure is worse than the disease.
So the framework has judgment built into its spine. Two ideas keep it from becoming process for its own sake.
Rigor scales with blast radius. The heavyweight rules — migrations, rollout strategy, scalability tradeoffs — apply rigorously to production-grade work: database schema changes, API contracts, auth flows, payment logic, anything user-facing in a live product. For a UI tweak, a copy edit, a prototype, a throwaway script? They relax. The first thing I establish on any real work block is whether we’re building an MVP or shipping to production. The rules bend accordingly.
Rules are safeguards, not gates. The default posture is “here are the risks and tradeoffs — proceed?” not “work cannot continue until every concern is resolved.” Questions get batched into a single checkpoint instead of dribbling out one interruption at a time. And when there’s a decision to make, the model leads with a recommendation — “I’d go with B because X; A and C are the alternatives” — instead of dumping a menu of equivalent options on me.
The rules exist to prevent silent decisions on substantive work. Small changes don’t need every rule. That’s not a loophole; it’s the design.
Why bother writing it down
I could keep all of this in my head and correct the AI as it goes. But correction-in-the-moment doesn’t scale, and it doesn’t persist across sessions. Writing it down turns a vague sense of “the AI keeps doing annoying things” into a contract the model reads before it touches anything.
It also did something I didn’t expect: it made me a better engineer. Naming the principles — surface tradeoffs, validate logic early, stay in scope, report honestly — sharpened how I think about my own work, not just how I direct the AI’s.
That’s the meta-lesson here. The best use of an AI assistant isn’t to offload your judgment. It’s to externalize your standards so clearly that the machine can hold you both to them.
The first week I used Claude with these rules, I cut down the back and forth iterations substantially, reducing a five day project effort to one day. Would like to hear YOUR experiences with it.
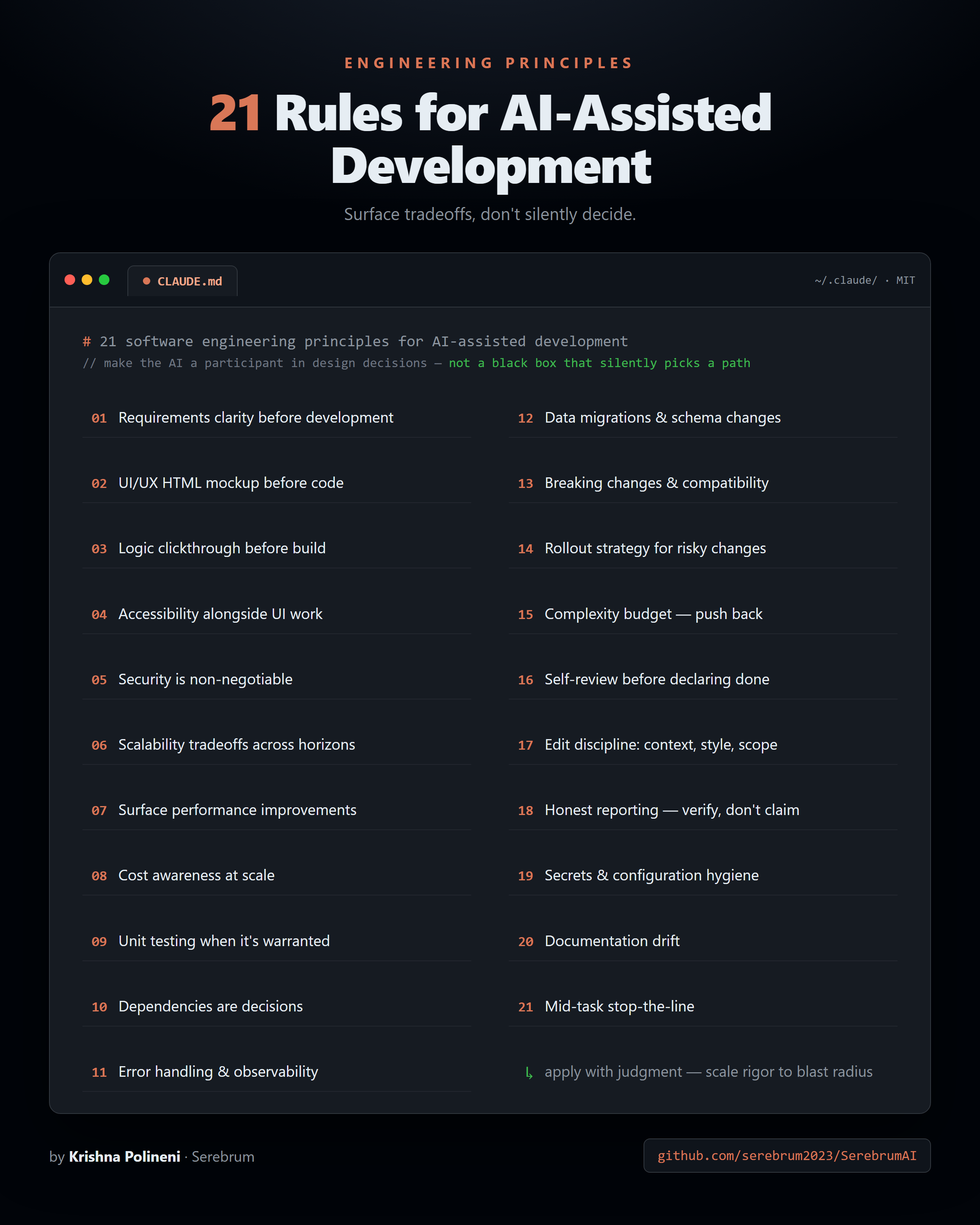
The 21 rules
The full list — requirements, UI mockups, logic prototypes, accessibility, security, scalability, performance, cost, testing, dependencies, observability, migrations, breaking changes, rollout, complexity, self-review, edit discipline, honest reporting, secrets, documentation drift, and stopping mid-task when an assumption breaks — lives here:
→ github.com/serebrum2023/SerebrumAI
It’s an MIT-licensed CLAUDE.md you can drop straight into your own setup. Take it, fork it, argue with it. If you think I’m missing one — or that one of mine is wrong — I genuinely want to hear it.
Because that’s the whole point, isn’t it. Don’t decide silently. Surface the tradeoff.
Praise: Spot on with identifying the risk of "silent decisions." In AI-driven development, state drift and hidden technical debt compound rapidly because LLMs default to greedy token selection pathways that maximize immediate plausibility over long-term architectural coherence. Explicitly enforcing a CLAUDE.md to break the agent out of its default "hallucinate-and-patch" loop is an excellent way to reclaim deterministic control over design patterns and maintain dependency boundaries.
Critique: While prototyping logic via throwaway HTML click-throughs works for high-level business flows, it introduces a dangerous abstraction leak for performance, concurrent state synchronization, or low-level API design. A more robust, automation-friendly alternative is pushing the model to generate a strict OpenAPI spec, an ASCII state-machine diagram, or a comprehensive suite of behavior-driven development (BDD) integration tests prior to writing production code. This catches edge cases deterministically and scales better than manual visual verification.